|
Statistical Inference, Decision Theory and Hypothesis Testing |

|
It is often necessary to make decisions about the characteristics of populations from the knowledge of sample quantities, called sample statistics. The study of these statistical decisions, the process behind them, and the degree of certainty attributed to them, is called statistical inference.
When making a statistical decision, assumptions about the populations in question must be made. That is to say, statements about the population's unknown quantities, or population parameters, are formulated, which may be true or false. These assumptions are called statistical hypotheses and the process of testing them is referred to as hypothesis testing.
A null hypothesis, commonly denoted ![]() , is a statistical hypothesis formulated for the purpose of rejection and usually implies equality. It is assumed to be true until evidence indicates otherwise. For example, if we want to test whether a certain brand of chocolate,
, is a statistical hypothesis formulated for the purpose of rejection and usually implies equality. It is assumed to be true until evidence indicates otherwise. For example, if we want to test whether a certain brand of chocolate, ![]() , tastes better than all the other brands,
, tastes better than all the other brands, ![]() , the null hypothesis will assume that it does not as
, the null hypothesis will assume that it does not as ![]() .
.
An alternative hypothesis, commonly denoted ![]() or
or ![]() , represents an alternative to the null hypothesis, or a claim that can only be true when the null hypothesis is false. Depending on the nature of the null hypothesis, three alternative hypotheses are possible:
, represents an alternative to the null hypothesis, or a claim that can only be true when the null hypothesis is false. Depending on the nature of the null hypothesis, three alternative hypotheses are possible:
Statistical decisions are not error-free. The error of rejecting a null hypothesis (hold it false) when it is true is called a type I error, whereas the error of not rejecting a null hypothesis (hold it true) when it is false is called a type II error.
|
|
|
|
Type I error |
Correct decision |
|
Correct decision |
Type II error |
The probability of making a type I error in a hypothesis test is called the significance level, ![]() , of the test. The point at which the significance level takes place is called the critical point—the point past which a null hypothesis is rejected. The complement of the significance level,
, of the test. The point at which the significance level takes place is called the critical point—the point past which a null hypothesis is rejected. The complement of the significance level, ![]() , is called the confidence level of the test.
, is called the confidence level of the test.
The probability of making a type II error, usually denoted ![]() , depends on the chosen significance level, the sample size and the true value of the parameter under consideration. The complement of
, depends on the chosen significance level, the sample size and the true value of the parameter under consideration. The complement of ![]() ,
, ![]() , represents the probability of not making a type II error and is called the power of the test.
, represents the probability of not making a type II error and is called the power of the test.
The performance of a test is characterized by its significance level and power, but because the true value of the parameter under consideration is rarely known, power values must be reported in curves, referred to as power curves, where power is calculated for a range of values of the parameter under consideration.
| At this time, Predictive Systems Lab does not report power values. |
The P-value of a hypothesis test represents the smallest significance level at which a null hypothesis can be rejected for the resulting test statistic.
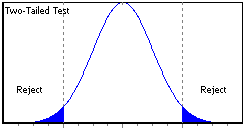
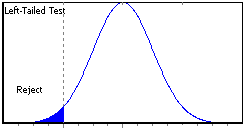
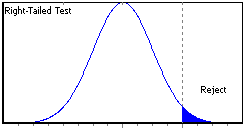
There are two methods for rejecting a null hypothesis in favor of an alternative. The first method is referred to as the critical point method, which indicates the rejection of a null hypothesis when the resulting statistic falls outside the confidence level region, or acceptance region, past the critical point, in what is called the rejection region. The second method, or P-value method, indicates the rejection of a null hypothesis when the reported P-value is smaller than the significance level of the test (see the following table and figures).
Reject a null hypothesis if
|
||
Test
|
Critical Point |
P-Value |
Two-Tailed
|
Computed statistic < Left critical point OR Computed statistic > Right critical point
|
Reported left P-Value1 < Significance level OR Reported right P-Value1 > 2-Significance level
|
Left-Tailed
|
Computed statistic < Left critical point
|
Reported left P-Value < Significance level
|
Right-Tailed
|
Computed statistic > Right critical point
|
Reported right P-Value > 1-Significance level
|
(1) Reported two-tailed P-values are doubled in two-tailed tests.
Graphical representation of statistical tests, where white areas under the curve equal the confidence level, shaded areas equal the significance level, and dotted lines the critical points. Significance levels and P-values correspond to areas at the tails, whereas critical points and test statistics correspond to points in the abscissa.
Sponsored
Try Predictive Systems Lab
Need Help?
Contact support