Backpropagation is the method used to iteratively approximate a multi layer neural network to some underlying function by modifying the network's neural connection weights. It starts by computing the error function (cost function) for the network with respect to the connection weights, W, at every iteration as follows:
![]() ,
,
where ![]() is the ith target value,
is the ith target value, ![]() the output of the ith neuron of the output layer, and N the number of target values.
the output of the ith neuron of the output layer, and N the number of target values.
The process continues to calculate the derivatives of this function at every network layer, starting at the output layer and continuing in reverse order as follows:
| · | For the output layer: |
The derivative of the error function for the ith neuron of the output layer L with respect to ![]() , the weight for the output of the jth neuron in the previous layer L-1, is given by:
, the weight for the output of the jth neuron in the previous layer L-1, is given by:
![]()
Where ![]() is the output of the jth neuron of the previous layer L-1,
is the output of the jth neuron of the previous layer L-1, ![]() is an optional scaling coefficient,
is an optional scaling coefficient, ![]() the derivative of the activation function,
the derivative of the activation function, ![]() the number of neurons in the previous layer, and
the number of neurons in the previous layer, and ![]() the weight for the output of the kth neuron of the previous layer.
the weight for the output of the kth neuron of the previous layer.
If we let
![]()
then
![]()
| · | For every other layer except the input layer: |
The partial derivatives for a hidden layer, ![]() , may be computed when the
, may be computed when the ![]() values for the following layer are known:
values for the following layer are known:
![]()
![]()
Where ![]() .
.
Once the partial derivatives of the error function are known, the neural connection weights are updated in the opposite direction of the value of the derivative with the intention of modifying the weights to a value where the derivative of the error function is zero, or the point at which in theory the function reaches a minima and the network attains an optimal approximation to the underlying function:
| · | If the momentum rate is zero: |
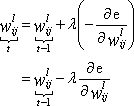
| · | If the momentum rate is based on the last change: |
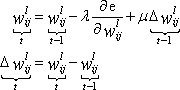
| · | If the momentum rate is based on the last gradient: |
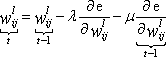
Where ![]() is the learning rate,
is the learning rate, ![]() is the momentum rate, and
is the momentum rate, and ![]() and
and ![]() refer to values calculated in this update and in the previous update, respectively.
refer to values calculated in this update and in the previous update, respectively.
Sponsored
Try Predictive Systems Lab
Need Help?
Contact support